Our Methods
Why we use K-means Clustering
For this project, we wanted to be able to categorize songs by similar genres using machine learning, but given the spotify data that we are using, it proved to be difficult for various different reasons. While our dataset included a genres column for our tracks, there were too many genres to work with (over 2000!), and so many of them had nuanced differences and similarities that could not have otherwise been separated by their titles. For example, Japanese Country and Country Music in general would contain the same "Country" string, but they would have sounded completely different from each other, while Swedish Rock and Italian Punk Rock would have been similar in sound and attributes.
There were plenty of other issues that we ran into. In our dataset, we had some genres that could've been Umbrella terms, but this wasn't applicable for every situation. Psychadelic Rock, Alternative Rock, Indie Rock, and Spanish Rock could've been under the "Rock" umbrella genre, but if we also put Punk Rock, Slow Rock, Pop Rock, and Classic Rock all under the "Rock" category, we would have extremely diverse results, causing unnecessary noise in our analysis.
We eventually came to the conclusion that the best machine learning algorithm to use would be K-means Clustering. This is because we wouldn't have to aggregate genres in our dataset to something more malleable. Instead, we wouldn't have any labels for our machine learning algorithm. The clustering would be determined by the attributes that best described our tracks. These attributes were:
The cleaning process
The Spotify dataset we had originally wasn't exactly clean. The first issue was the scaling. In order to prepare the dataset to be used in the machine learning model, we would need all the attributes to be measured on a homogenous scale. After scaling all the attributes from a scale of 0 to 1, we needed to explode our tracks DataFrame, merge in order to obtain genres, and then implode the DataFrames to get rid of duplicate values. Then the data would be prepped for the AzureML segment.
Once the model's output has been evaluated and saved, we would clean the data further, grouping the data by tracks and their id in order to query recommended songs and cluster results, then by cluster assignment for further analysis, as will be mentioned again in the Cluster Visuals segment.
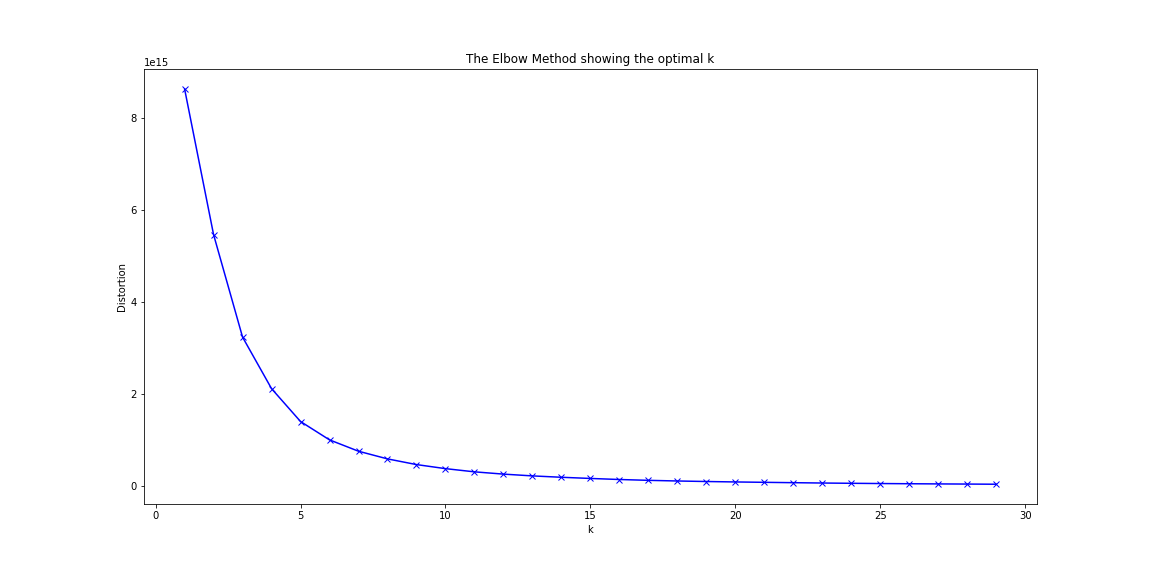
Getting the optimal number of clusters
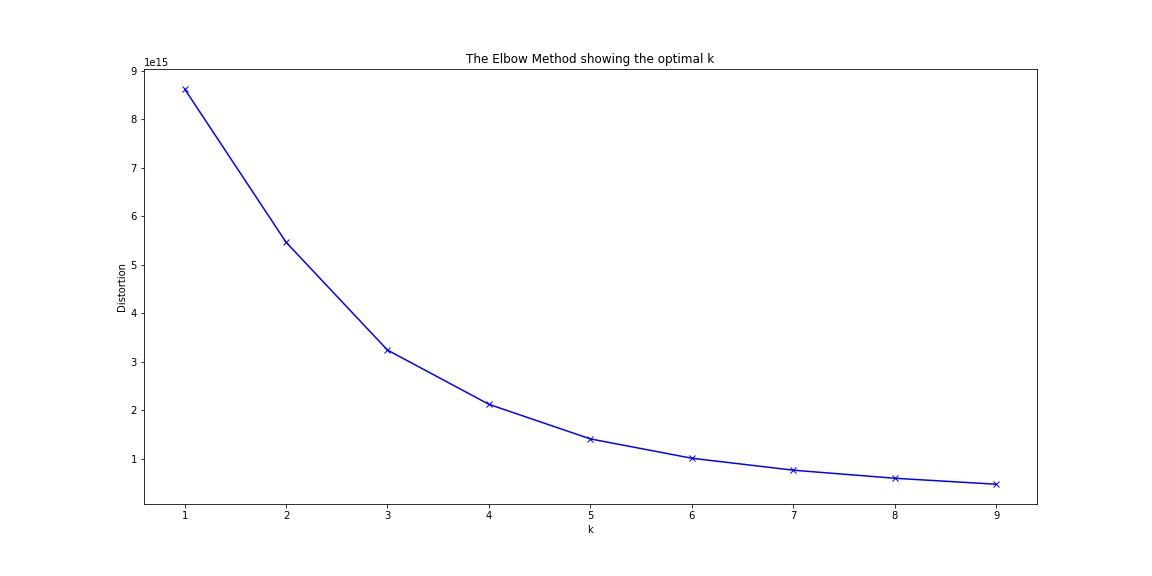
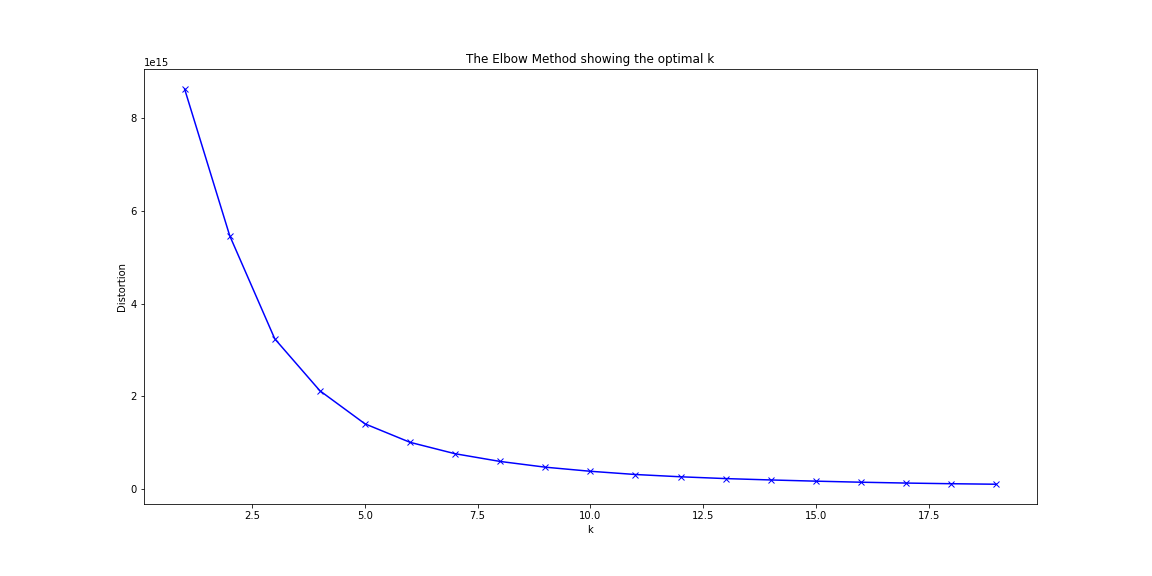
One of the most important steps in training a k-means model is determining the optimal amount of clusters to use for analyzing your data. K-means clustering requires that the user specify how many clusters (k) be generated in the model; however, the answer to this question may be subjective and typically does not have a true definitive number. By looping through and testing a range of cluster numbers (k), the amount of distortion (average euclidean squared distance from centroid of the respective clusters) can be evaluated. One should choose the number of clusters where adding another cluster would not decrease the distortion by a significant degree. In our model, we determined the optimal number between 8-10 clusters. Considering the large amount of tracks in our datasets, 10 was chosen to give higher complexity and variety in our analysis.
Using AzureML
After finding the optimal number of clusters (10 clusters), we got down to work with AzureML. We set the amount of clusters we wanted to output to 10, we trained the clustering model with the above listed attributes, we assigned the data to the clusters, and we outputted and evaluated the data. This would put all the songs in our massive dataset into 10 clusters based on how the clusters weighted these attributes. Doing this, we could truly see how nuanced our genres column was. And we also saw several trends in the clusters we outputted.
Clustering Visuals
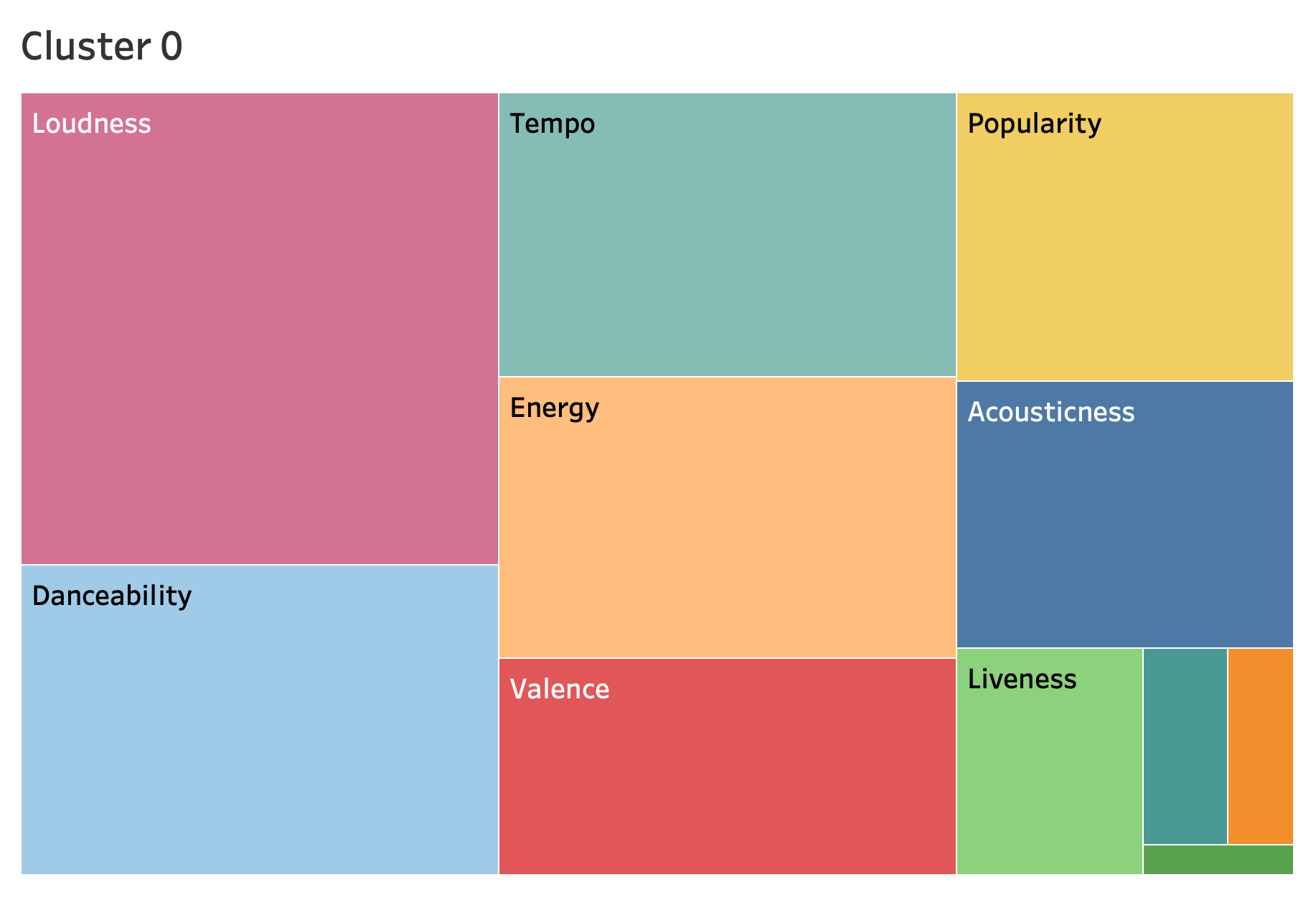
Here we have two visualizations as a result of our clustering. The first one is a visual of how the cluster weighs each attribute, and how each one is put in perspective, size-wised, against all the other attributes. This is an aggregated average of the respective, selected cluster.
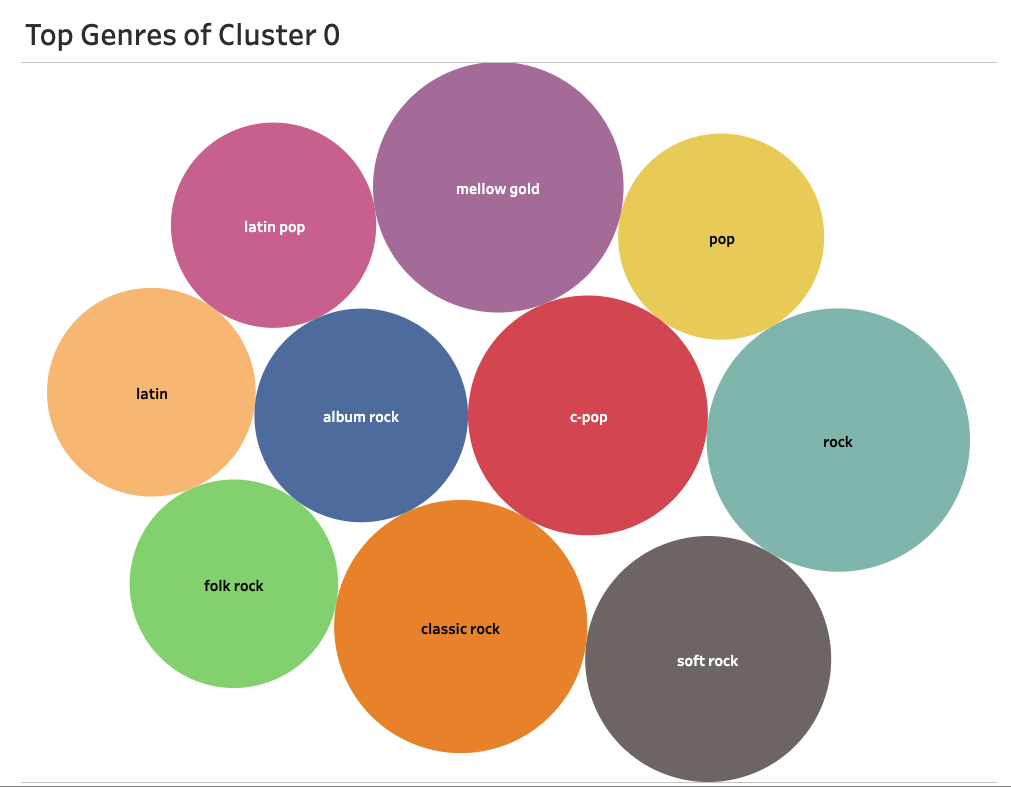
The next plot is a tree map of the genres associated with each artist's track after being clustered. With only the attributes, it is difficult to understand how the algorithm places these tracks in their respective cluster, but it is much more comprehensible when we visualize the genres that happened to be clustered together.